What is Machine Learning?
Machine learning (ML) is a category of algorithm that allows software applications to become more accurate in predicting outcomes by building a mathematical model of sample data, known as “training data”, in order to make predictions or decisions without being explicitly programmed to perform the task.It is seen as a subset of artificial intelligence.
How machine learning works?
Machine learning algorithms are often categorized as supervised or unsupervised.
- Supervised machine learning algorithms require a data scientist or data analyst with machine learning skills to provide both input and desired output, in addition to furnishing feedback about the accuracy of predictions during algorithm training. Data scientists determine which variables, or features, the model should analyze and use to develop predictions. Once training is complete, the algorithm will apply what was learned to new data.
- In contrast, Unsupervised machine learning algorithms are used when the information used to train is neither classified nor labeled. Unsupervised learning studies how systems can infer a function to describe a hidden structure from unlabeled data. The system doesn’t figure out the right output, but it explores the data and can draw inferences from datasets to describe hidden structures from unlabeled data.
Types of machine learning algorithms
Just as there are nearly limitless uses of machine learning, there is no shortage of machine learning algorithms. They range from the fairly simple to the highly complex. Here are a few of the most commonly used models:
- Decision trees – These models use observations about certain actions and identify an optimal path for arriving at a desired outcome.
- K-means clustering – This model groups a specified number of data points into a specific number of groupings based on like characteristics.
- Neural networks – These deep learning models utilize large amounts of training data to identify correlations between many variables to learn to process incoming data in the future.
- Reinforcement learning – This area of deep learning involves models iterating over many attempts to complete a process. Steps that produce favorable outcomes are rewarded and steps that produce undesired outcomes are penalized until the algorithm learns the optimal process.

Top 10 real-life examples of Machine Learning
- Image Recognition
- Speech Recognition
- Medical diagnosis
- Statistical Arbitrage
- Learning associations
- Classification
- Prediction
- Extraction
- Regression
- Financial Services
PHP-ML – Machine Learning library for PHP
PHP-ML is a machine learning library for PHP. Given, PHP is probably not the best choice when it comes to machine learning, but sometimes one is limited in technology stack choices, so it’s good have options like this one.
Fresh approach to Machine Learning in PHP. Algorithms, Cross Validation, Neural Network, Preprocessing, Feature Extraction and much more in one library.
PHP-ML requires PHP >= 7.1.
Simple example of classification:
require_once __DIR__ . ‘/vendor/autoload.php’;
use Phpml\Classification\KNearestNeighbors;
$samples = [[1, 3], [1, 4], [2, 4], [3, 1], [4, 1], [4, 2]];
$labels = [‘a’, ‘a’, ‘a’, ‘b’, ‘b’, ‘b’];
$classifier = new KNearestNeighbors();
$classifier->train($samples, $labels);
$classifier->predict([3, 2]);
// return ‘b’
Installation
Currently this library is in the process of developing, but You can install it with Composer:
composer require php-ai/php-ml
Features
- Association rule Learning
– Apriori - Classification
– SVC
– k-Nearest Neighbors
– Naive Bayes - Regression
– Least Squares
– SVR - Clustering
– k-Means
– DBSCAN - Metric
– Accuracy
– Confusion Matrix
– Classification Report - Workflow
– Pipeline - Neural Network
– Multilayer Perceptron Classifier - Cross Validation
– Random Split
– Stratified Random Split - Feature Selection
– Variance Threshold
– SelectKBest - Preprocessing
– Normalization
– Imputation missing values - Feature Extraction
– Token Count Vectorizer
– Tf-idf Transformer - Datasets
– Array
– CSV
– Files
– SVM
– MNIST
– Ready to use:
* Iris
* Wine
* Glass - Models management
– Persistency - Math
– Distance
– Matrix
– Set
– Statistic
Example
Clustering Chicago robberies locations with k-means algorithm
The internet is full of interesting datasets. This time I want to show you data extracted from the Chicago Police Department’s CLEAR (Citizen Law Enforcement Analysis and Reporting) system.
Data preparation and visualization
To simplify the whole process I will use only one file Chicago_Crimes_2012_to_2017.csv where we can find 1 456 715 records from year 2012 to 2017. I want to extract only ROBBERY type, and only two columns: Latitude and Longitude:
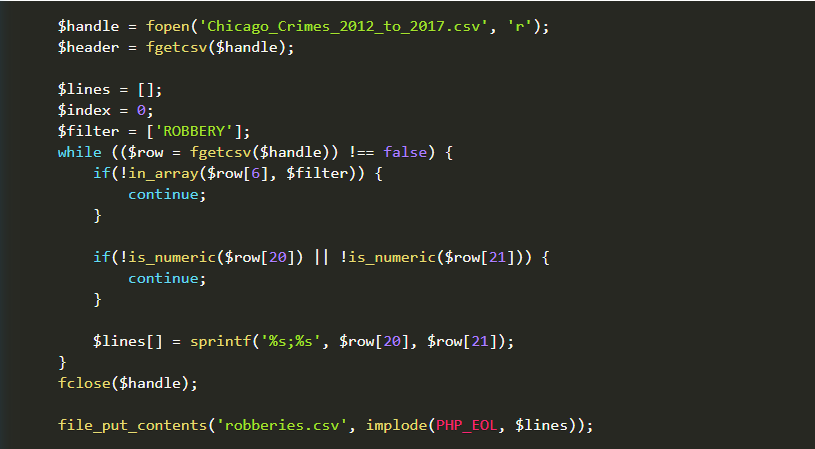
So let’s run this script and check generated file:
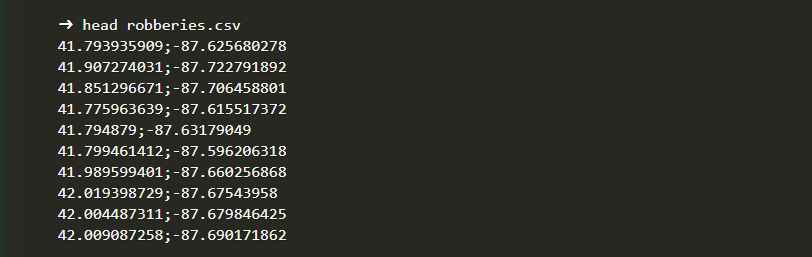
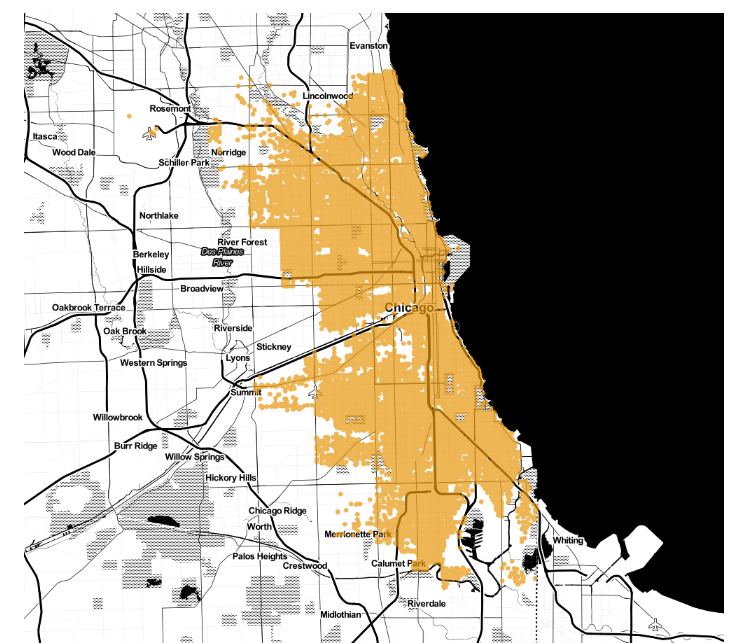
Everything looks good, but it is always better to try to visualize the data in order to be sure.
K-means algorithm
To understand the principles of this algorithm, we must introduce one new concept: centroid. A centroid is a representative of a given cluster or the center of a given group. Now we can split this algorithm in 4 simple steps:
Step 1 Choose the amount of centroids and the initial arrangement of them in space. For this algorithm, we need to predetermine how many groups we want to divide our set. Then we place the number of points in the space ().
The final result depends on the initial placement. Various techniques are used here to optimize its operation.
Step 2 In this step, we calculate the average distances of individual points and assign them to the nearest centroid.
Step 3 We are updating the location of our centroids. The new centroid coordinates are the arithmetic mean of the coordinates of all points having its group.
Final step The second and third steps are repeated until the convergence criterion is reached, which is most often the state in which the membership of the points to the classes has not changed.
K-means with php-ml
Ok, so you are wondering how to use k-means in php? With php-ml such things are really simple.

In this way, $clusters variable contains array with 3 arrays of our robberies locations.
$locations must be read from csv file prepared earlier:

Next I want to save another file with clustered data: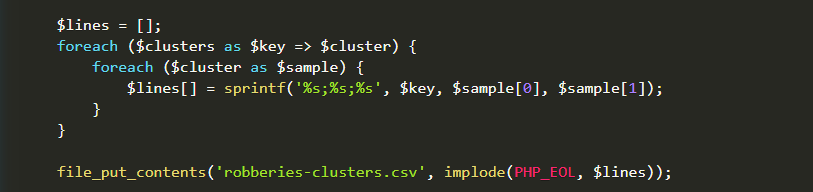
So now I have csv file with following structure: clusterIndex;latitude;longitude. With this simple python script I can create nice visualization map:
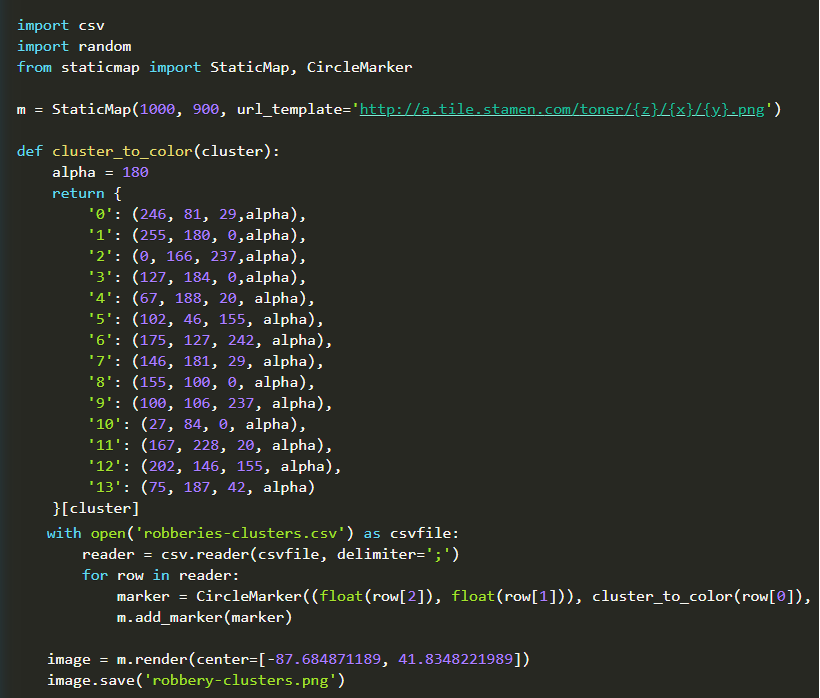
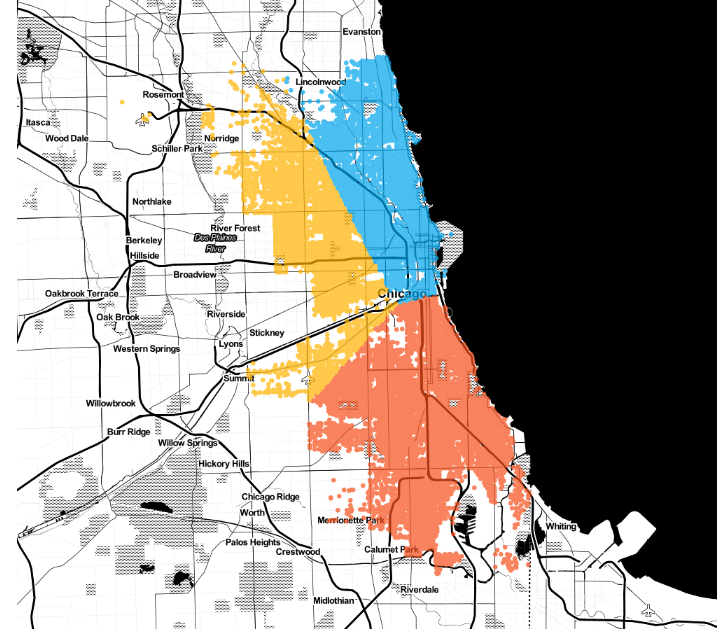
Let’s plot clustering results on Chicago city map. First k=3
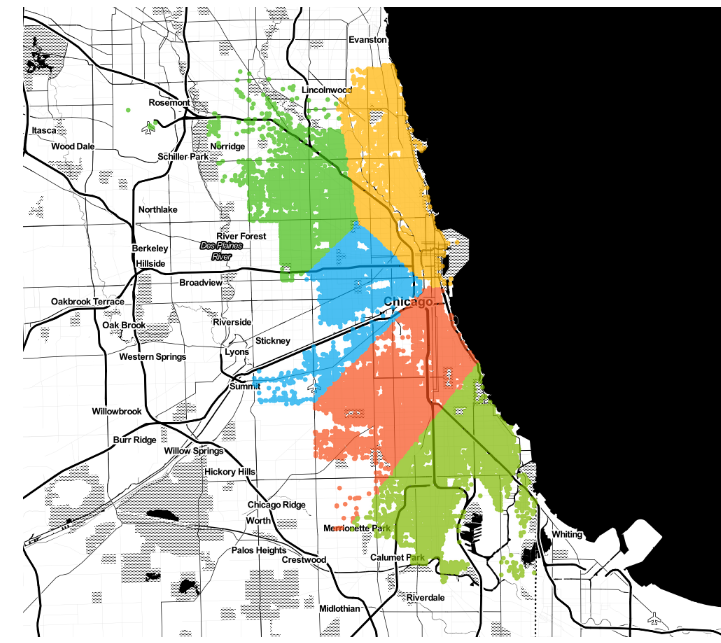
Nothing special, how about adding two more (k=5).
Choosing best k
One of the main questions that you may encounter while learning this algorithm is: how to choose the best k? The answer is not unambiguous. It may depend on many factors: business, technological or pre-imposes.
Conclusion
In a nutshell, we can say that machine learning is an incredible breakthrough in the field of artificial intelligence. And while machine learning has some frightening implications, these machine learning applications are one of the ways through which technology can improve our lives.
References:-
- https://www.expertsystem.com/machine-learning-definition/
- https://searchenterpriseai.techtarget.com/definition/machine-learning-ML
- https://bigdata-madesimple.com/top-10-real-life-examples-of-machine-learning/
- https://php-ml.readthedocs.io/en/latest/
- https://arkadiuszkondas.com/clustering-chicago-robberies-locations-with-k-means-algorithm/