BIG DATA
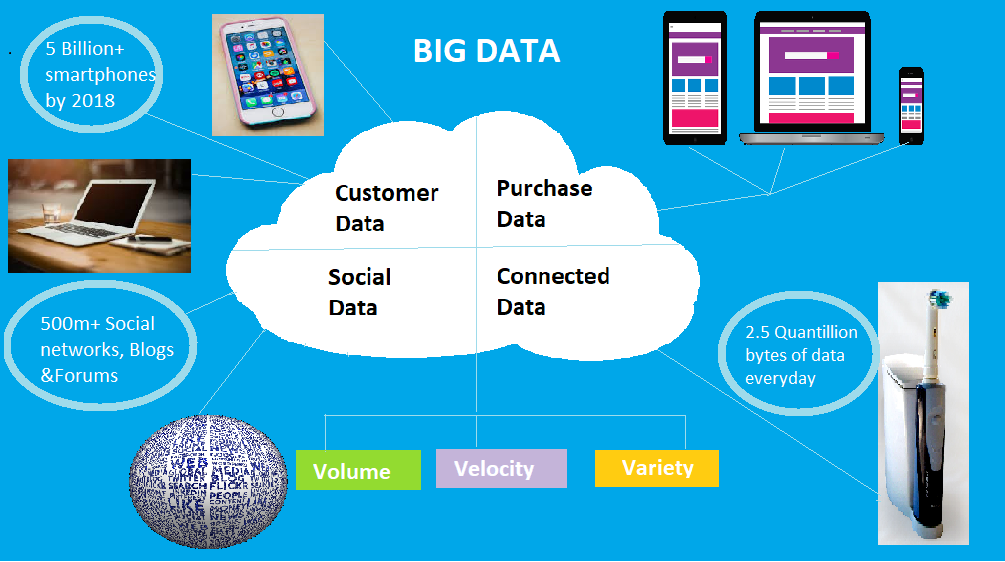
Big data is data sets that are so voluminous and complex that traditional data-processing application software is inadequate to deal with them. Big data challenges include capturing data, data storage, data analysis, search, sharing, transfer, visualization, querying, updating, information privacy and data source. It’s not the amount of data that is important, it’s what organizations do with the data that matters.Big data can be analyzed for insights that lead to better decisions and strategic business moves.
Big Data can be classified as follows:
Unstructured data comes from information that is not organized or easily interpreted by traditional databases or data models, and typically, it’s text-heavy. Metadata, Twitter tweets, and other social media posts are good examples of unstructured data.
Multi-structured data refers to a variety of data formats and types and can be derived from interactions between people and machines, such as web applications or social networks. A great example is web log data, which includes a combination of text and visual images along with structured data like form or transactional information.
The 3 V’s of Big data
Volume. Organizations collect data from a variety of sources, including business transactions, social media and information from sensor or machine-to-machine data. Volume refers to the large amount of data being generated.
Velocity. Data streams in at an unprecedented speed and must be dealt with in a timely manner. RFID tags, sensors and smart metering are driving the need to deal with torrents of data in near-real time.
Variety. Data comes in all types of formats – from structured, numeric data in traditional databases to unstructured text documents, email, video, audio, stock ticker data and financial transactions.
Why is Big Data Important?
The importance of big data doesn’t revolve around how much data you have, but what you do with it. You can take data from any source and analyze it to find answers that enable cost reductions, time reductions, new product development and optimized offerings, and smart decision making. When you combine big data with high-powered analytics, you can accomplish business-related tasks such as:
-
Determining root causes of failures, issues and defects in near-real time.
-
Generating coupons at the point of sale based on the customer’s buying habits.
-
Recalculating entire risk portfolios in minutes.
-
Detecting fraudulent behavior before it affects your organization.
Sources of Big Data
The various sources of big data are:
- Electronic files like audios, videos, pdfs, internet pages, etc.
- Social media networks
- Business Transactions
- Sensors connected to electronic devices
- RFID tags
- Machine-to-machine data
Who uses Big Data?
Big data affects organizations across practically every industry.-
Banking
-
Government
-
Manufacturing
-
Education
-
Health Care
-
Retail
Big Data is one of the best ways to collect and use feedback. An example where big data could be used is a company having their own products and services.It helps the company to understand how customers perceive their services and products. Thus, they are able to make necessary changes, and re-develop products.
When unstructured social media text is analyzed, it allows uncovering general feedback from customers. The company can even disintegrate the feedback in various geographical locations and demographic groups.
Big data provides with insights from analyzing the market and consumers. However, this data is not only valuable to the company, but also other parties. They can sell the non-personalized trend data to large industries operating in the same sector. Big Data tools allow to map the entire data landscape across the company. This allows to analyze all kinds of internal threats. With this information, they can keep the sensitive information safe.
APACHE HADOOP
Apache Hadoop is an open-source software framework for storage and large-scale processing of data-sets on clusters of commodity hardware. There are mainly 3 parts:
1.Hadoop Distributed File System (HDFS)
2.Hadoop MapReduce
3.Yet Another Resource Negotiator (YARN)
Hadoop Distributed File System (HDFS)
-
HDFS is the framework responsible for providing permanent, reliable and distributed storage.
-
A file on HDFS is split into multiple blocks and each is replicated within the Hadoop cluster.
-
A block on HDFS is a blob of data within the underlying file system with a default size of 64MB. The size of a block can be extended up to 256 MB based on the requirements.
-
HDFS stores the application data and file system metadata separately on dedicated servers.
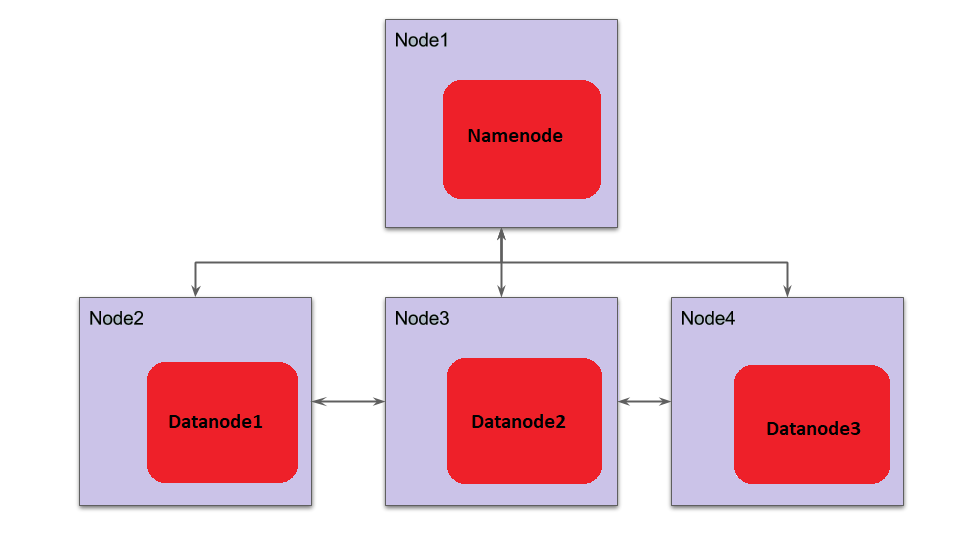
-
NameNode and DataNode are the two critical components of the Hadoop HDFS architecture.
-
Application data is stored on servers referred to as DataNodes and file system metadata is stored on servers referred to as NameNode.
-
HDFS replicates the file content on multiple DataNodes based on the replication factor to ensure reliability of data.
-
For the Hadoop architecture to be performance efficient, HDFS must satisfy certain pre-requisites:
-
All the hard drives should have a high throughput.
-
Good network speed to manage intermediate data transfer and block replications.
-
NameNode
All the files and directories in the HDFS namespace are represented on the NameNode by Inodes that contain various attributes like permissions, modification timestamp, disk space quota, namespace quota and access times. NameNode maps the entire file system structure into memory.
-
DataNode
DataNode perform CPU intensive jobs like semantic and language analysis, statistics and machine learning tasks, and I/O intensive jobs like clustering, data import, data export, search, decompression, and indexing. A DataNode needs lot of I/O for data processing and transfer.
On startup every DataNode connects to the NameNode and performs a handshake to verify the namespace ID and the software version of the DataNode. If either of them does not match then the Data Node shuts down automatically.
Hadoop MapReduce
-
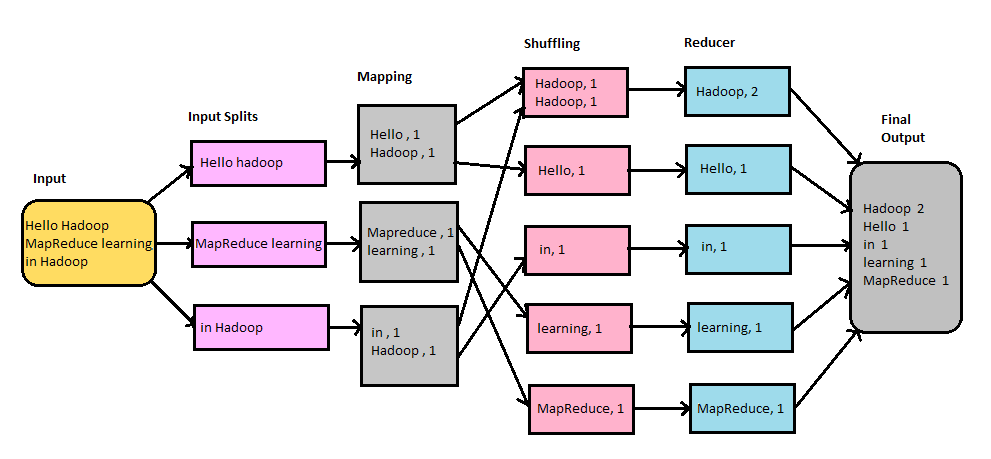
The heart of the distributed computation platform Hadoop is its java-based programming paradigm Hadoop MapReduce. Map function transforms the piece of data into key-value pairs and then the keys are sorted where a reduce function is applied to merge the values based on the key into a single output.
-
The processing of the Map phase begins where the Task Tracker extracts the input data from the splits. Map function is invoked for each record parsed by the “Input Format” which produces key-value pairs in the memory buffer. The memory buffer is then sorted to different reducer nodes by invoking the combine function.
-
On completion of the map task, Task Tracker notifies the Job Tracker. When all Task Trackers are done, the Job Tracker notifies the selected Task Trackers to begin the reduce phase.
-
Task Tracker reads the region files and sorts the key-value pairs for each key. The reduce function is then invoked which collects the aggregated values into the output file.
Yet Another Resource Negotiator (YARN)
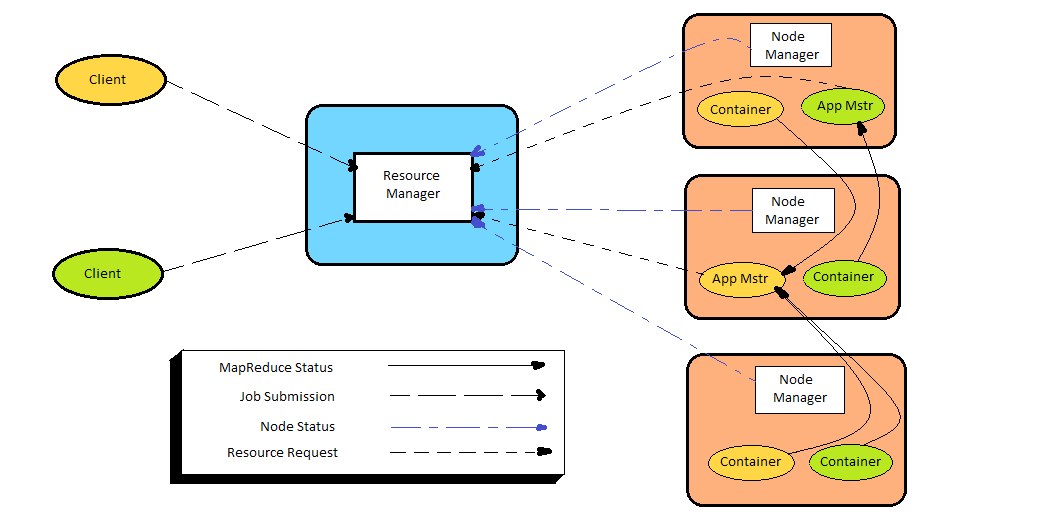
YARN Infrastructure is the framework responsible for providing the computational resources (e.g., CPUs, memory, etc.) needed for application executions.
-
Two important elements are:
-
Resource Manager
Resource Manager (one per cluster) is the master. It knows where the slaves are located and how many resources they have. It runs several services, the most important is the Resource Scheduler which decides how to assign the resources.
-
Node Manager
Node Manager (many per cluster) is the slave of the infrastructure. When it starts, it announces himself to the Resource Manager. Periodically, it sends heartbeat (Active signal) to the Resource Manager. Each Node Manager offers some resources to the cluster. Its resource capacity is the amount of memory and the number of VCores (Virtual Cores). At run-time, the Resource Scheduler will decide how to use this capacity. A Container is a fraction of the NM capacity and it is used by the client for running a program.
References
- https://searchdatamanagement.techtarget.com/definition/big-data
- http://www.hadoopadmin.co.in/sources-of-bigdata/
- https://whatis.techtarget.com/definition/3Vs
- https://www.dezyre.com/article/hadoop-architecture-explained-what-it-is-and-why-it-matters/317
- http://ercoppa.github.io/HadoopInternals/HadoopArchitectureOverview.html